

رونمایی از طرح 120 میلیون دلاری ابرکامپیوترهای «مقیاس مغز» در سال 2024
Graphcore از فناوری تراشه ی سه بعدی TSMC برای سرعت بخشی 40 درصدی به هوش مصنوعی بکار گیری میکند.
شرکت کامپیوتری انگلیسی Graphcore که در حیطه ی هوش مصنوعی فعال است، بدون اعمال تغییر در هستههای تخصصی پردازندههای هوش مصنوعی خود، عملکرد رایانههای خود را افزایش داد.
راز این کار بکارگیری از فناوری ادغام سه بعدی ویفر روی ویفر TSMC در حین ساخت برای اتصال یک تراشه ی انتقال نیرو به پردازنده هوش مصنوعی Graphcore بود.
به گفته مدیران Graphcore، تراشه ی ترکیبی جدید، به نام Bow، برای اولین بار در لندن، به عنوان اولین تراشهای که از اتصال ویفر روی ویفر سود میبرد، به بازار آمد.
قرار گیری سیلیکون انتقال انرژی به این معنی است که Bow میتواند سریع تر ( یعنی 1.85 گیگاهرتز در مقابل 1.35 گیگاهرتز) و با ولتاژ کمتری نسبت به نسل قبلی خود کار کند.
این انرژی به شبکههای عصبی رایانهها توانایی میدهد که با 40 درصد سرعت بیشتر و 16 درصد انرژی کمتر نسبت به نسل قبلی خود کار کنند.
نکته مهم این است که کاربران این پیشرفت را بدون هیچ تغییری در نرم افزار خود دریافت میکنند.
سایمون نولز، موسس و مدیر فنی Graphcore میگوید: «ما وارد عصر بستهبندی پیشرفته میشویم که در آن قالبهای سیلیکونی چندگانه قرار است با هم مونتاژ شوند تا مزایای عملکردی را که میتوانیم از پیشرفت روزافزون در مسیر قانون مور به دست آوریم، تکمیل کنیم.
Bow و مدل قبلی آن، Colossus MK2 با استفاده از فناوری یکسان، N7 TSMC طراحی شدند.
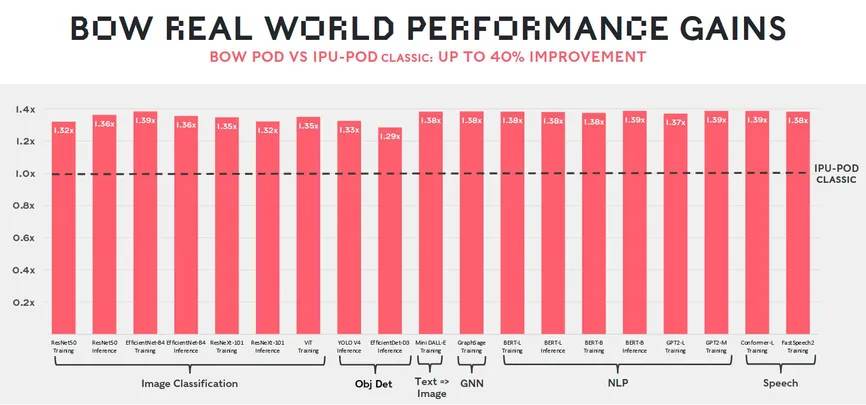
در مقایسه با نسل قبلی Graphcore ، رایانههای جدید میتوانند شبکههای عصبی کلیدی را حدود 40 درصد سریعتر راهاندازی کنند.
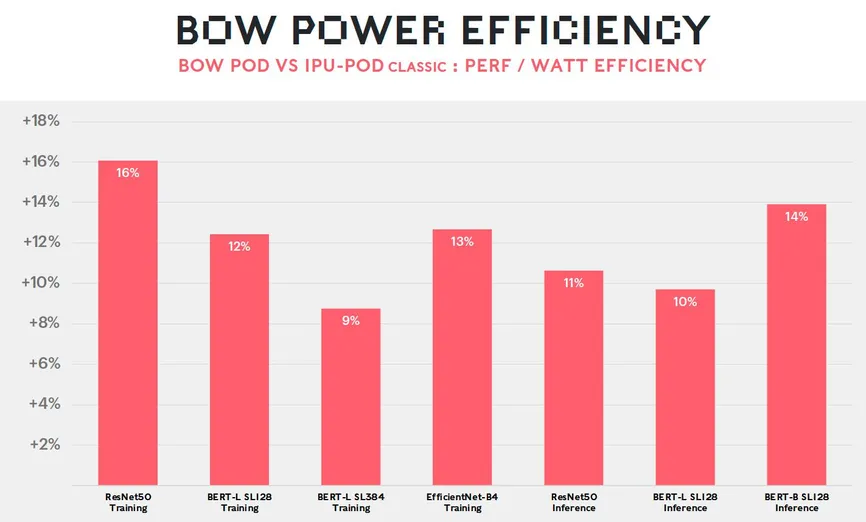
سیستمهای جدید در تقویت شبکههای عصبی کلیدی تا 16 درصد کارآمدتر هستند.
در سایر فناوریهای تراشه سه بعدی روی هم انباشته، مانند Foveros تولید کمپانی اینتل، تراشههای از قبل جدا به تراشههای دیگر یا به ویفرها متصل میشوند.
در فناوریSoIC WoW کمپانی TSMC، دو ویفر تراشه ی کامل، به هم متصل میشوند. روی هر تراشه پدهای مسی موجود است و زمانی که ویفرها در یک راستا قرار میگیرند، این پدها کاملا با هم مطابقت دارند. هنگامی که دو ویفر به هم فشرده میشوند، پدهای مسی با هم ترکیب میشوند. نولز میگوید: شما میتوانید این را نوعی جوش سرد بین لنتها در نظر بگیرید. سپس ویفر بالایی تا چند میکرومتر نازک میشود و ویفر چسبان خرد و به صورت تراشه در میآید.
ویفرهای Graphcore، مملو از پردازندههای هوش مصنوعی نسل دوم این شرکت هستند (این شرکت آنها را IPU مینامد به معنی واحد پردازش هوشمند) با 1472 هسته IPU و 900 مگابایت حافظه روی تراشه. این پردازندهها قبلاً در سیستمهای تجاری استفاده میشدند و در آخرین دور آزمایشهای MLPerf نمایش خوبی داشتند. ویفر دیگر دارای مجموعهای از تراشههای انتقال نیرو بود. این تراشهها فاقد ترانزیستور یا سایر اجزای فعال هستند. در عوض، آنها با خازنها و اتصالات عمودی به نام گذرگاههای سیلیکونی بستهبندی شدهاند. این یکی، اتصالات برق و دادهای که از طریق تراشه برق به پردازنده منتقل میشود را ایجاد میکند.
اما تفاوت واقعی را این خازنها ایجاد میکنند.
این اجزا در شیارهای عمیق و باریکی در سیلیکون تشکیل میشوند، دقیقاً مانند خازنهای ذخیره کننده بیت در DRAM. با قرار دادن این مخازن شارژ بسیار نزدیک به ترانزیستورها، انتقال برق آسان میشود و به هستههای IPU اجازه میدهد با ولتاژ پایینتر و سرعت بیشتر کار کنند. بدون تراشه انتقال نیرو، IPU باید ولتاژش را به بالاتر از سطح واقعی خود افزایش دهد تا در فرکانس 1.85 گیگاهرتز کار کند و در نتیجه انرژی بسیار بیشتری مصرف کند. با تراشه نیرو، میتواند به آن نرخ ساعت برسد و در عین حال انرژی کمتری نیز مصرف کند.
مدیران Graphcore می گویند که در فناوری ویفر روی ویفر حجم بین اتصالات تراشهها بیشتر از زمانی است که از فناوری اتصال تراشههای جداگانه به ویفر استفاده میشد. با این حال، یکی از نگرانیهای دیرینه در مورد این تکنیک، مشکل “آزمودن تراشه پیش از بستهبندی” بود. یعنی همیشه در یک دسته ویفر چند تراشه وجود دارد که نقص دارد. و پیوند دو ویفر، تعداد تراشههای معیوب حاصل را دو برابر میکند. راه حل Graphcore این است که اجازه دهد تا حدی این اتفاق رخ بدهد. مانند برخی دیگر از پردازندههای جدید هوش مصنوعی، IPU از تعداد زیادی هستههای پردازشی تکراری و در نتیجه اضافی و سایر بخشها تشکیل شده است. نایجل تون، یکی از بنیانگذاران و مدیرعامل Graphcore میگوید، میتوان با استفاده از فیوزهای داخلی، تراشههای خراب را از بقیه IPU جدا شد.
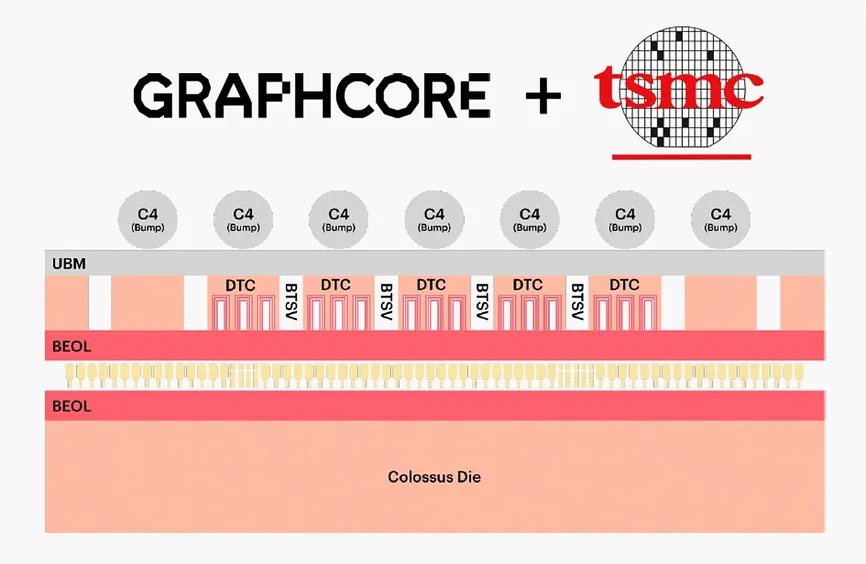
فناوری ویفر روی ویفر TSMC منجر به یک تراشه پردازشگر [پایین] میشود که توسط پدهای مسی [زرد] به یک تراشه انتقال نیرو [بالا] متصل میشود. سیگنالها و نیرو از برجستگیهای لحیم کاری [خاکستری] از تراشه بالایی عبور میکند.
اگرچه محصول جدید هیچ ترانزیستوری بر روی تراشه انتقال نیرو ندارد، اما ممکن است این ترانزیستورها به زودی در بازار عرضه شوند.
نولز میگوید بکارگیری این فناوری برای انتقال نیرو، تنها اولین قدم برای ما می باشد. در آینده ای نزدیک بسیار فراتر از آن پیش خواهیم رفت.
Graphcore برنامههایی را برای آینده ی نزدیک فاش کرد و اعلام کرد که ابررایانههایی خواهد ساخت که میتوانند هوش مصنوعی با مقیاس مغز باشند، آنهایی که صدها تریلیون پارامتر در یک شبکه عصبی دارند. کامپیوتر Good که به افتخار ریاضیدان بریتانیایی I.J. “Jack” Good نامگذاری شد، قادر به انجام بیش از 10 اگزافلاپس – 10 میلیارد میلیارد– عملیات ممیز شناور است. Good می تواند از 512 سیستم با 8192 IPU به همراه ذخیره سازی انبوه، CPU و شبکه تشکیل شده باشد. همچنین دارای 4 پتابایت حافظه و پهنای باند بیش از 10 پتابایت در ثانیه خواهد بود. Graphcore تخمین میزند که هر ابرکامپیوتر حدود 120 میلیون دلار قیمت بیابد و تا سال 2024 آماده تحویل گردد.
تون میگوید: «زمانی که Graphcore را راهاندازی کردیم… این ایده همیشه در ذهن ما وجود داشت که یک کامپیوتر فوقهوشمند بسازیم که از توانایی مغز انسان پیشی بگیرد. “و این همان چیزی است که ما اکنون روی آن کار میکنیم.”
رقیب Graphcore با نام Cerebras Systems قبلاً پرچم خود را در تلاش برای هوش مصنوعی در مقیاس مغز بالا برده است. این شرکت یک سیستم حافظه ی خارجی و راهی برای اتصال چندین کامپیوتر ایجاد کرد که به رایانههایش اجازه میدهد شبکههای عصبی را با صدها تریلیون پارامتر راهاندازی کند.










